
Zookeeper中一致性共识算法ZAB(Zookeeper Atomic Broadcast protocol)改进了Raft算法,提供一致性的元数据存储,多用在分布式系统中共享元数据信息。下面来看看具体细节。

1.ZAB介绍
ZAB协议全称就是ZooKeeper Atomic Broadcast protocol,是ZooKeeper用来实现一致性的算法,分成如下4个阶段。
先来解释下部分名词:
- electionEpoch:每执行一次leader选举,electionEpoch就会自增,用来标记leader选举的轮次
- peerEpoch:每次leader选举完成之后,都会选举出一个新的peerEpoch,用来标记事务请求所属的轮次
- zxid:事务请求的唯一标记,由leader服务器负责进行分配。由2部分构成,高32位是上述的peerEpoch,低32位是请求的计数,从0开始。所以由zxid我们就可以知道该请求是哪个轮次的,并且是该轮次的第几个请求。
- lastProcessedZxid:最后一次commit的事务请求的zxid
Leader election:
leader选举过程,electionEpoch自增,在选举的时候lastProcessedZxid越大,越有可能成为leader
Discovery:
第一:leader收集follower的lastProcessedZxid,这个主要用来通过和leader的lastProcessedZxid对比来确认follower需要同步的数据范围
第二:选举出一个新的peerEpoch,主要用于防止旧的leader来进行提交操作(旧leader向follower发送命令的时候,follower发现zxid所在的peerEpoch比现在的小,则直接拒绝,防止出现不一致性)
Synchronization:
follower中的事务日志和leader保持一致的过程,就是依据follower和leader之间的lastProcessedZxid进行,follower多的话则删除掉多余部分,follower少的话则补充,一旦对应不上则follower删除掉对不上的zxid及其之后的部分然后再从leader同步该部分之后的数据
Broadcast:
正常处理客户端请求的过程。leader针对客户端的事务请求,然后提出一个议案,发给所有的follower,一旦过半的follower回复OK的话,leader就可以将该议案进行提交了,向所有follower发送提交该议案的请求,leader同时返回OK响应给客户端
上面简单的描述了上述4个过程,这4个过程的详细描述在zab的paper中可以找到,但是我看了之后基本和zab的源码实现上相差有点大,这里就不再提zab paper对上述4个过程的描述了,下面会详细的说明ZooKeeper源码中是具体怎么来实现的
2.ZAB协议源码实现
先看下ZooKeeper整体的实现情况,如下图所示
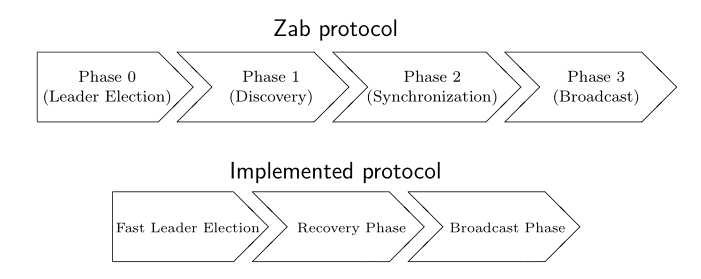
上述实现中Recovery Phase包含了ZAB协议中的Discovery和Synchronization。
2.1 重要的数据介绍
加上前面已经介绍的几个名词
- long lastProcessedZxid:
最后一次commit的事务请求的zxid - LinkedList
committedLog、long maxCommittedLog、long minCommittedLog:
ZooKeeper会保存最近一段时间内执行的事务请求议案,个数限制默认为500个议案。上述committedLog就是用来保存议案的列表,上述maxCommittedLog表示最大议案的zxid,minCommittedLog表示committedLog中最小议案的zxid。 - ConcurrentMap<Long, Proposal> outstandingProposals
Leader拥有的属性,每当提出一个议案,都会将该议案存放至outstandingProposals,一旦议案被过半认同了,就要提交该议案,则从outstandingProposals中删除该议案 - ConcurrentLinkedQueue
toBeApplied
Leader拥有的属性,每当准备提交一个议案,就会将该议案存放至该列表中,一旦议案应用到ZooKeeper的内存树中了,然后就可以将该议案从toBeApplied中删除
对于上述几个参数,整个Broadcast的处理过程可以描述为:
- leader针对客户端的事务请求(leader为该请求分配了zxid),创建出一个议案,并将zxid和该议案存放至leader的outstandingProposals中
- leader开始向所有的follower发送该议案,如果过半的follower回复OK的话,则leader认为可以提交该议案,则将该议案从outstandingProposals中删除,然后存放到toBeApplied中
- leader对该议案进行提交,会向所有的follower发送提交该议案的命令,leader自己也开始执行提交过程,会将该请求的内容应用到ZooKeeper的内存树中,然后更新lastProcessedZxid为该请求的zxid,同时将该请求的议案存放到上述committedLog,同时更新maxCommittedLog和minCommittedLog
- leader就开始向客户端进行回复,然后就会将该议案从toBeApplied中删除
2.2 Fast Leader Election
leader选举过程要关注的要点:
- 所有机器刚启动时进行leader选举过程
- 如果leader选举完成,刚启动起来的server怎么识别到leader选举已完成
投票过程有3个重要的数据:
ServerState
目前ZooKeeper机器所处的状态有4种,分别是- LOOKING:进入leader选举状态
- FOLLOWING:leader选举结束,进入follower状态
- LEADING:leader选举结束,进入leader状态
- OBSERVING:处于观察者状态
HashMap<Long, Vote> recvset
用于收集LOOKING、FOLLOWING、LEADING状态下的server的投票HashMap<Long, Vote> outofelection
用于收集FOLLOWING、LEADING状态下的server的投票(能够收集到这种状态下的投票,说明leader选举已经完成)
下面就来详细说明这个过程:
1. serverA首先将electionEpoch自增,然后为自己投票
serverA会首先从快照日志和事务日志中加载数据,就可以得到本机器的内存树数据,以及lastProcessedZxid(这一部分后面再详细说明)
初始投票Vote的内容:
- proposedLeader:ZooKeeper Server中的myid值,初始为本机器的id
- proposedZxid:最大事务zxid,初始为本机器的lastProcessedZxid
- proposedEpoch:peerEpoch值,由上述的lastProcessedZxid的高32得到
- 然后该serverA向其他所有server发送通知,通知内容就是上述投票信息和electionEpoch信息
2. serverB接收到上述通知,然后进行投票PK
如果serverB收到的通知中的electionEpoch比自己的大,则serverB更新自己的electionEpoch为serverA的electionEpoch
如果该serverB收到的通知中的electionEpoch比自己的小,则serverB向serverA发送一个通知,将serverB自己的投票以及electionEpoch发送给serverA,serverA收到后就会更新自己的electionEpoch
在electionEpoch达成一致后,就开始进行投票之间的pk,规则如下:
1 | /* |
就是优先比较proposedEpoch,然后优先比较proposedZxid,最后优先比较proposedLeader
pk完毕后,如果本机器投票被pk掉,则更新投票信息为对方投票信息,同时重新发送该投票信息给所有的server。
如果本机器投票没有被pk掉,则看下面的过半判断过程
3. 根据server的状态来判定leader
如果当前发来的投票的server的状态是LOOKING状态,则只需要判断本机器的投票是否在recvset中过半了,如果过半了则说明leader选举就算成功了,如果当前server的id等于上述过半投票的proposedLeader,则说明自己将成为了leader,否则自己将成为了follower
如果当前发来的投票的server的状态是FOLLOWING、LEADING状态,则说明leader选举过程已经完成了,则发过来的投票就是leader的信息,这里就需要判断发过来的投票是否在recvset或者outofelection中过半了
同时还要检查leader是否给自己发送过投票信息,从投票信息中确认该leader是不是LEADING状态。这个解释如下:
因为目前leader和follower都是各自检测是否进入leader选举过程。leader检测到未过半的server的ping回复,则leader会进入LOOKING状态,但是follower有自己的检测,感知这一事件,还需要一定时间,在此期间,如果其他server加入到该集群,可能会收到其他follower的过半的对之前leader的投票,但是此时该leader已经不处于LEADING状态了,所以需要这么一个检查来排除这种情况。
2.3 Recovery Phase
一旦leader选举完成,就开始进入恢复阶段,就是follower要同步leader上的数据信息
1 通信初始化
leader会创建一个ServerSocket,接收follower的连接,leader会为每一个连接会用一个LearnerHandler线程来进行服务
2 重新为peerEpoch选举出一个新的peerEpoch
f ollower会向leader发送一个Leader.FOLLOWERINFO信息,包含自己的peerEpoch信息
leader的LearnerHandler会获取到上述peerEpoch信息,leader从中选出一个最大的peerEpoch,然后加1作为新的peerEpoch。
然后leader的所有LearnerHandler会向各自的follower发送一个Leader.LEADERINFO信息,包含上述新的peerEpoch
follower会使用上述peerEpoch来更新自己的peerEpoch,同时将自己的lastProcessedZxid发给leader
leader的所有LearnerHandler会记录上述各自follower的lastProcessedZxid,然后根据这个lastProcessedZxid和leader的lastProcessedZxid之间的差异进行同步
3 已经处理的事务议案的同步
判断LearnerHandler中的lastProcessedZxid是否在minCommittedLog和maxCommittedLog之间
LearnerHandler中的lastProcessedZxid和leader的lastProcessedZxid一致,则说明已经保持同步了
如果lastProcessedZxid在minCommittedLog和maxCommittedLog之间
从lastProcessedZxid开始到maxCommittedLog结束的这部分议案,重新发送给该LearnerHandler对应的follower,同时发送对应议案的commit命令
上述可能存在一个问题:即lastProcessedZxid虽然在他们之间,但是并没有找到lastProcessedZxid对应的议案,即这个zxid是leader所没有的,此时的策略就是完全按照leader来同步,删除该follower这一部分的事务日志,然后重新发送这一部分的议案,并提交这些议案
如果lastProcessedZxid大于maxCommittedLog
则删除该follower大于部分的事务日志
如果lastProcessedZxid小于minCommittedLog
则直接采用快照的方式来恢复
4 未处理的事务议案的同步
LearnerHandler还会从leader的toBeApplied数据中将大于该LearnerHandler中的lastProcessedZxid的议案进行发送和提交(toBeApplied是已经被确认为提交的)
LearnerHandler还会从leader的outstandingProposals中大于该LearnerHandler中的lastProcessedZxid的议案进行发送,但是不提交(outstandingProposals是还没被被确认为提交的)
5 将LearnerHandler加入到正式follower列表中
意味着该LearnerHandler正式接受请求。即此时leader可能正在处理客户端请求,leader针对该请求发出一个议案,然后对该正式follower列表才会进行执行发送工作。这里有一个地方就是:
上述我们在比较lastProcessedZxid和minCommittedLog和maxCommittedLog差异的时候,必须要获取leader内存数据的读锁,即在此期间不能执行修改操作,当欠缺的数据包已经补上之后(先放置在一个队列中,异步发送),才能加入到正式的follower列表,否则就会出现顺序错乱的问题
同时也说明了,一旦一个follower在和leader进行同步的过程(这个同步过程仅仅是确认要发送的议案,先放置到队列中即可等待异步发送,并不是说必须要发送过去),该leader是暂时阻塞一切写操作的。
对于快照方式的同步,则是直接同步写入的,写入期间对数据的改动会放在上述队列中的,然后当同步写入完成之后,再启动对该队列的异步写入。
上述的要理解的关键点就是:既要不能漏掉,又要保证顺序
6 LearnerHandler发送Leader.NEWLEADER以及Leader.UPTODATE命令
该命令是在同步结束之后发的,follower收到该命令之后会执行一次版本快照等初始化操作,如果收到该命令的ACK则说明follower都已经完成同步了并完成了初始化
leader开始进入心跳检测过程,不断向follower发送心跳命令,不断检是否有过半机器进行了心跳回复,如果没有过半,则执行关闭操作,开始进入leader选举状态
LearnerHandler向对应的follower发送Leader.UPTODATE,follower接收到之后,开始和leader进入Broadcast处理过程
2.4 Broadcast Phase
前面其实已经说过了,参见2.1中的内容
3 特殊情况的注意点
3.1 事务日志和快照日志的持久化和恢复
先来看看持久化过程:
Broadcast过程的持久化
leader针对每次事务请求都会生成一个议案,然后向所有的follower发送该议案
follower接收到该议案后,所做的操作就是将该议案记录到事务日志中,每当记满100000个(默认),则事务日志执行flush操作,同时开启一个新的文件来记录事务日志
同时会执行内存树的快照,snapshot.[lastProcessedZxid]作为文件名创建一个新文件,快照内容保存到该文件中leader shutdown过程的持久化
一旦leader过半的心跳检测失败,则执行shutdown方法,在该shutdown中会对事务日志进行flush操作
再来说说恢复:
事务快照的恢复
第一:会在事务快照文件目录下找到最近的100个快照文件,并排序,最新的在前
第二:对上述快照文件依次进行恢复和验证,一旦验证成功则退出,否则利用下一个快照文件进行恢复。恢复完成更新最新的lastProcessedZxid事务日志的恢复
第一:从事务日志文件目录下找到zxid大于等于上述lastProcessedZxid的事务日志
第二:然后对上述事务日志进行遍历,应用到ZooKeeper的内存树中,同时更新lastProcessedZxid
第三:同时将上述事务日志存储到committedLog中,并更新maxCommittedLog、minCommittedLog
由此我们可以看到,在初始化恢复的时候,是会将所有最新的事务日志作为已经commit的事务来处理的
也就是说这里面可能会有部分事务日志还没真实提交,而这里全部当做已提交来处理。这个处理简单粗暴了一些,而raft对老数据的恢复则控制的更加严谨一些。
3.2 follower挂了之后又重启的恢复过程
一旦leader挂了,上述leader的2个集合
ConcurrentMap<Long, Proposal> outstandingProposals
ConcurrentLinkedQueue
就无效了。他们并不在leader恢复的时候起作用,而是在系统正常执行,而某个follower挂了又恢复的时候起作用。
我们可以看到在上述2.3的恢复过程中,会首先进行快照日志和事务日志的恢复,然后再补充leader的上述2个数据中的内容。
3.3 同步follower失败的情况
目前leader和follower之间的同步是通过BIO方式来进行的,一旦该链路出现异常则会关闭该链路,重新与leader建立连接,重新同步最新的数据
3.4 对client端是否一致
客户端收到OK回复,会不会丢失数据?
客户端没有收到OK回复,会不会多存储数据?
客户端如果收到OK回复,说明已经过半复制了,则在leader选举中肯定会包含该请求对应的事务日志,则不会丢失该数据
客户端连接的leader或者follower挂了,客户端没有收到OK回复,目前是可能丢失也可能没丢失,因为服务器端的处理也很简单粗暴,对于未来leader上的事务日志都会当做提交来处理的,即都会被应用到内存树中。
同时目前ZooKeeper的原生客户端也没有进行重试,服务器端也没有对重试进行检查。这一部分到下一篇再详细探讨与raft的区别
4 未完待续
本文有很多细节,难免可能疏漏,还请指正。
4.1 问题
这里留个问题供大家思考下:
raft每次执行AppendEntries RPC的时候,都会带上当前leader的新term,来防止旧的leader的旧term来执行相关操作,而ZooKeeper的peerEpoch呢?达到防止旧leader的效果了吗?它的作用是干什么呢?
Suffering is the best teacher of life.
书山有路勤为径,学海无涯苦作舟。
欢迎关注微信公众号:【程序员写书】
喜欢宠物的朋友可以关注:【电巴克宠物Pets】
一起学习,一起进步。