
spark号称比mr快100倍,tez也号称比mr快100倍,那么他们之间为什么有这么大的差距呢?下面来看看。

为什么性能远超mr?
- spark和tez都是基于dag方式处理数据
- tez源于mr,核心思想是将map和reduce两个操作进一步拆分,即map被拆分Input、Processor、Sort、Merge和Output,reduce被拆分为Input、Shuffle、Sort、Merge和Output,这样分解后的元数据操作就可以随意组合,产生新的操作,这些操作经过一些程序组装后,形成一个大的DAG作业,可以将多个map依赖合并为1个,这样只需写一次hdfs;mr的话,有多少个依赖map就有多少个任务;
- spark直接可以将job输出的中间结果写入内存中;
mr和tez对比图如下: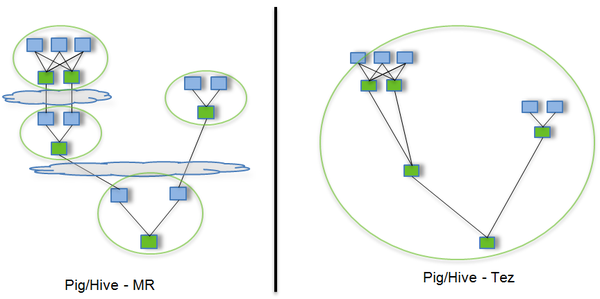
使用场景的区别
- spark是一个通用计算引擎,提供实时、离线、机器学习等多种计算方式,适合迭代计算;
- tez作为一个框架工具,特定为hive和pig提供计算;
优势
- spark属于内存计算,map阶段计算结果可以缓存在内存中。支持多种运行模式,可以跑在standalone、yarn、memos等资源调度框架上,而tez只能跑在yarn上;
- tez能够及时地释放资源,重启container,节省调度时间,对内存的资源要求率不高,资源利用率高,属于细粒度资源调度;而spark如果存在迭代计算时,container会一直占用着资源,资源利用率不高,属于粗粒度资源调度;
总结
tez与spark两者并不矛盾,不存在冲突,在实际生产中,如果数据需要快速处理而且资源充足,则可以选择spark;如果资源是瓶颈,则可以使用tez;可以根据不同场景不同数据层次做出选择;这个总结同样也适合spark与mr的比较;
Asking cost nothing.
书山有路勤为径,学海无涯苦作舟。
欢迎关注微信公众号:【程序员写书】
喜欢宠物的朋友可以关注:【电巴克宠物Pets】
一起学习,一起进步。