
Impala和Hive两者都是构建在Hadoop之上的大数据查询分析工具,他们之间有什么区别和联系呢?

1.从客户端来看
Impala和Hive有许多相同之处,如数据表元数据、ODBC/JDBC驱动、SQL语法等,但是他们还是有不同之处的,Hive适合长时间的批处理查询分析,而Impala适合实时交互式查询分析。Impala给数据分析人员提供了快速实验、验证想法的大数据分析工具,可以先使用hive进行数据转换处理,然后使用Impala在Hive处理后的结果集之上进行快速的数据分析。
下图可以看下Impala和Hive的区别与联系: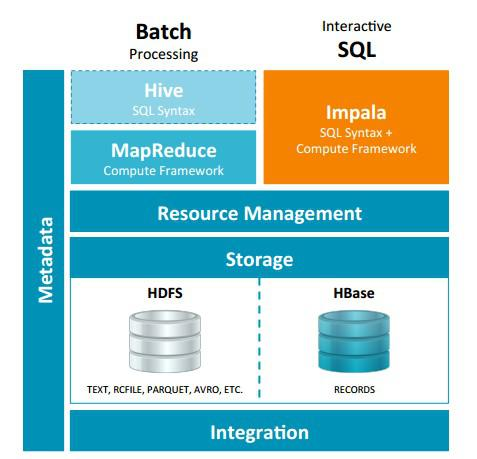
2.从技术上来看
- 执行计划:Impala没有使用Mr进行并行计算,mr是面向批处理的方式,而Impala是面向交互式的并行计算。Impala把整个查询解析成执行计划树,在分发执行计划后,使用拉式获取计算结果,把结果数据组成按执行树流式传递汇集,减少了中间结果写入磁盘的步骤,再从磁盘读取数据的开销;
- 执行方式:Impala使用服务的方式,避免每次执行查询都要启动的开销,即相比Hive节省了启动mapreduce的开销;
- 数据存储:都支持把数据存储在HDFS和HBase;
- 元数据:使用相同的元数据;
- Sql解析:比较相似,都是通过语法分析生成的执行计划;
- 数据流:
- Hive:采用推的方式,每一个计算节点task执行完成之后将计算结果一起推送给下一个task;
- Impala:采用拉的方式,后续节点通过getNext,主动向前面的节点拉取数据,以此方式获取结果以流的形式返回给客户端,只要有1条结果数据,就会立即展现在客户端,不用等到全部处理完,更符合交互式查询使用;
3.总结
所以,Hive适合复杂的批处理查询,数据转换任务,而Impala适合实时数据分析,配合Hive使用,对hive的结果数据进行实时分析。
Heath is certainly more important than money.
书山有路勤为径,学海无涯苦作舟。
欢迎关注微信公众号:【程序员写书】
喜欢宠物的朋友可以关注:【电巴克宠物Pets】
一起学习,一起进步。