
目前运行环境是这样的:
1 | hive version: 3.1.0 |
默认tez引擎
此表数据量: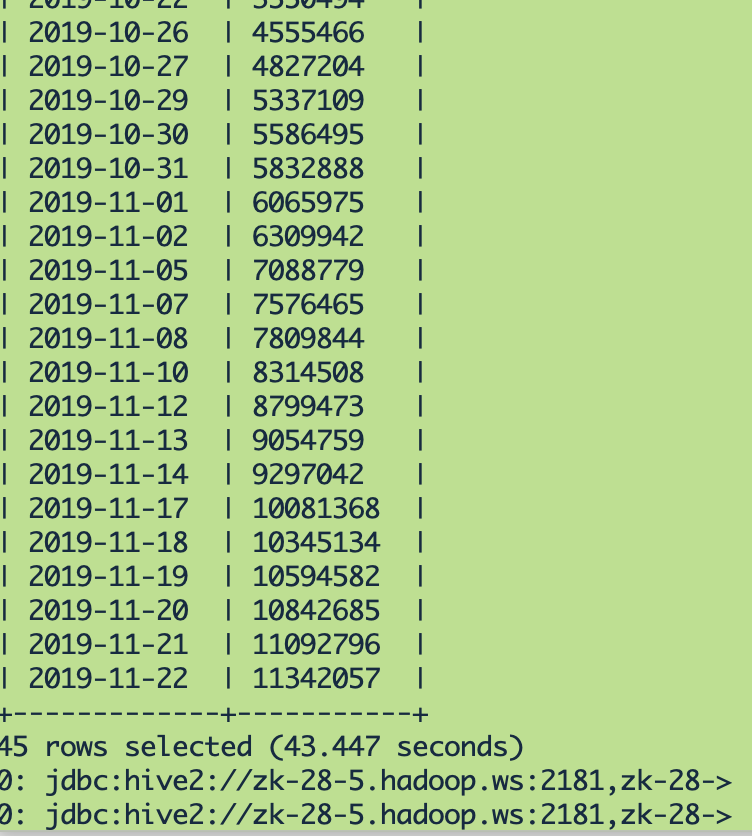
原来设置的参数如下:
1 | set hive.merge.mapfiles=true; |
运行时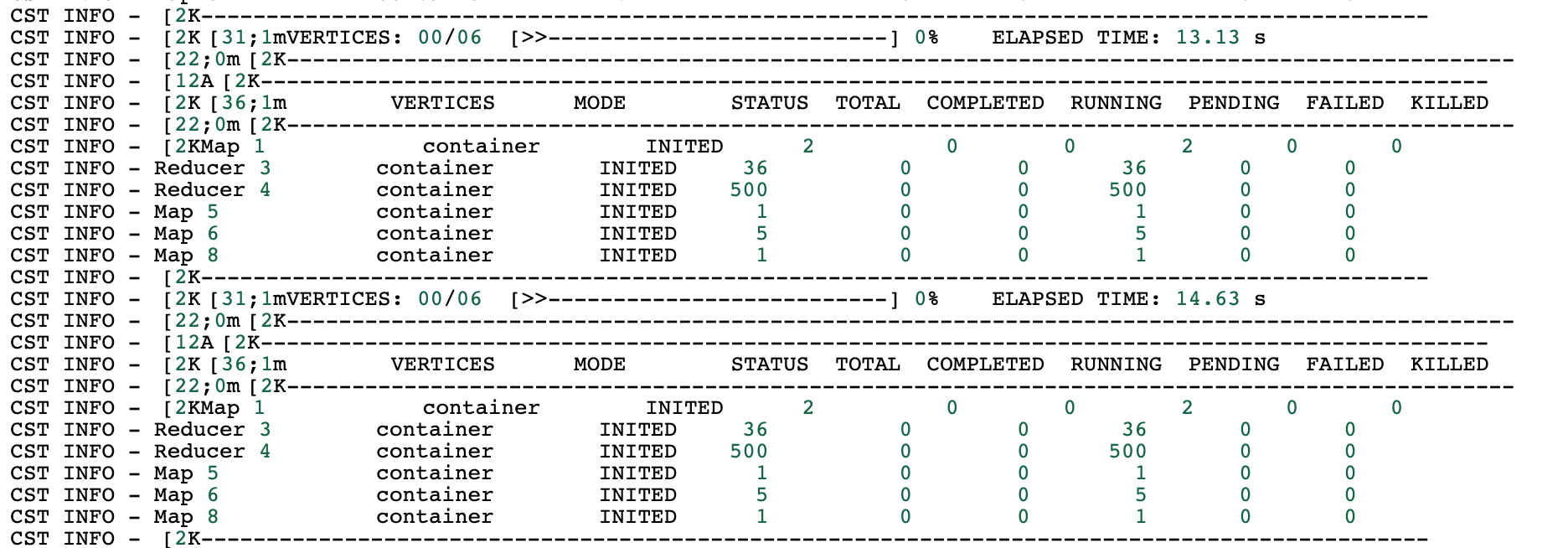
运行结果出现如下错误: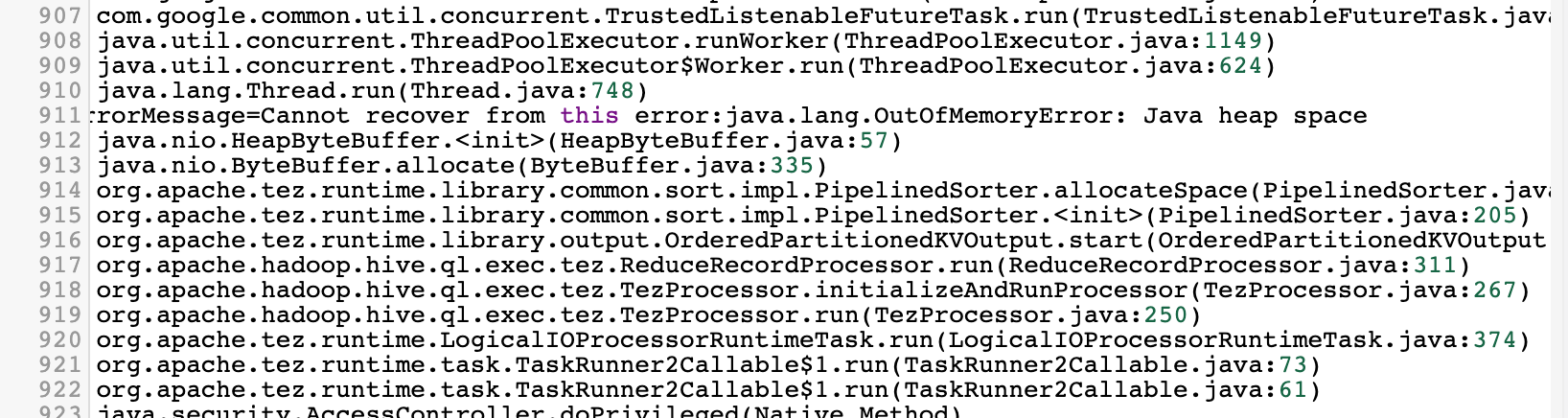
分析:
- 此表数据量很大;
- 运行时500个reducer中每个reducer所承载的数据量很大;
昨天此任务运行成功,去hdfs看下结果数据文件情况:
发现结果文件只有5个,而且每个文件34M,可想而知1个reducer当时拉取了大量的数据做聚合,这是导致reducer内存溢出的原因,于是设置reducer个数:
1 | set mapred.reduce.tasks=1000; |
添加参数后运行时: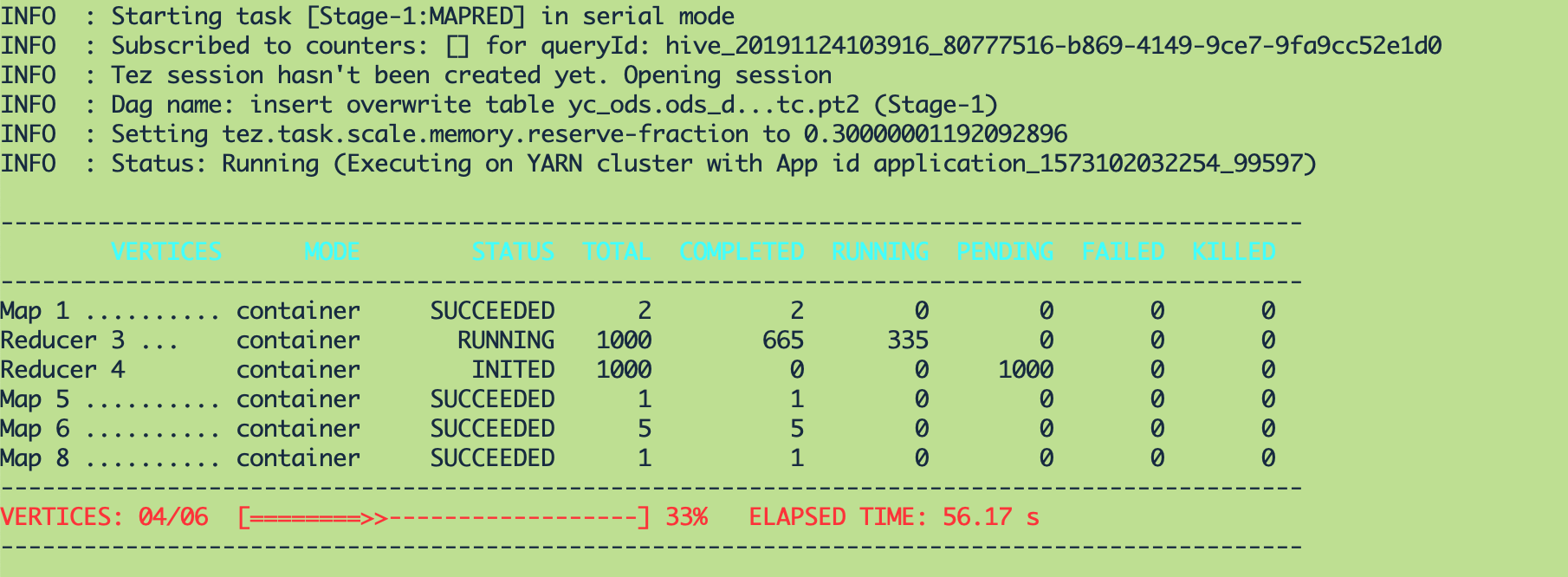
添加参数后运行结果文件如下: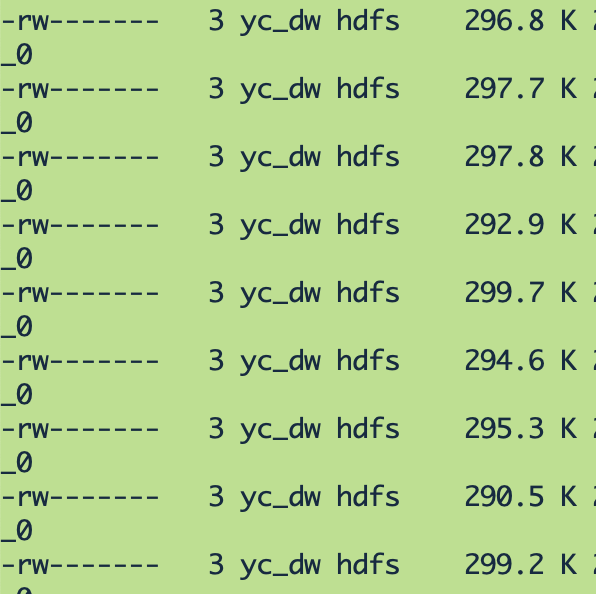
解决。
A man is not old until his regrets take place of his dreams.
书山有路勤为径,学海无涯苦作舟。
欢迎关注微信公众号:【程序员写书】
喜欢宠物的朋友可以关注:【电巴克宠物Pets】
一起学习,一起进步。