
最近在做实时数仓相关工作,了解到一些皮毛,但是大致方向还是对的,目前有一些眉目和进展,就跟大家讲讲。今天讲讲实时数据接入吧,怎么将数据实时接入到数据湖或者数据仓库。![]()
来看看流程图: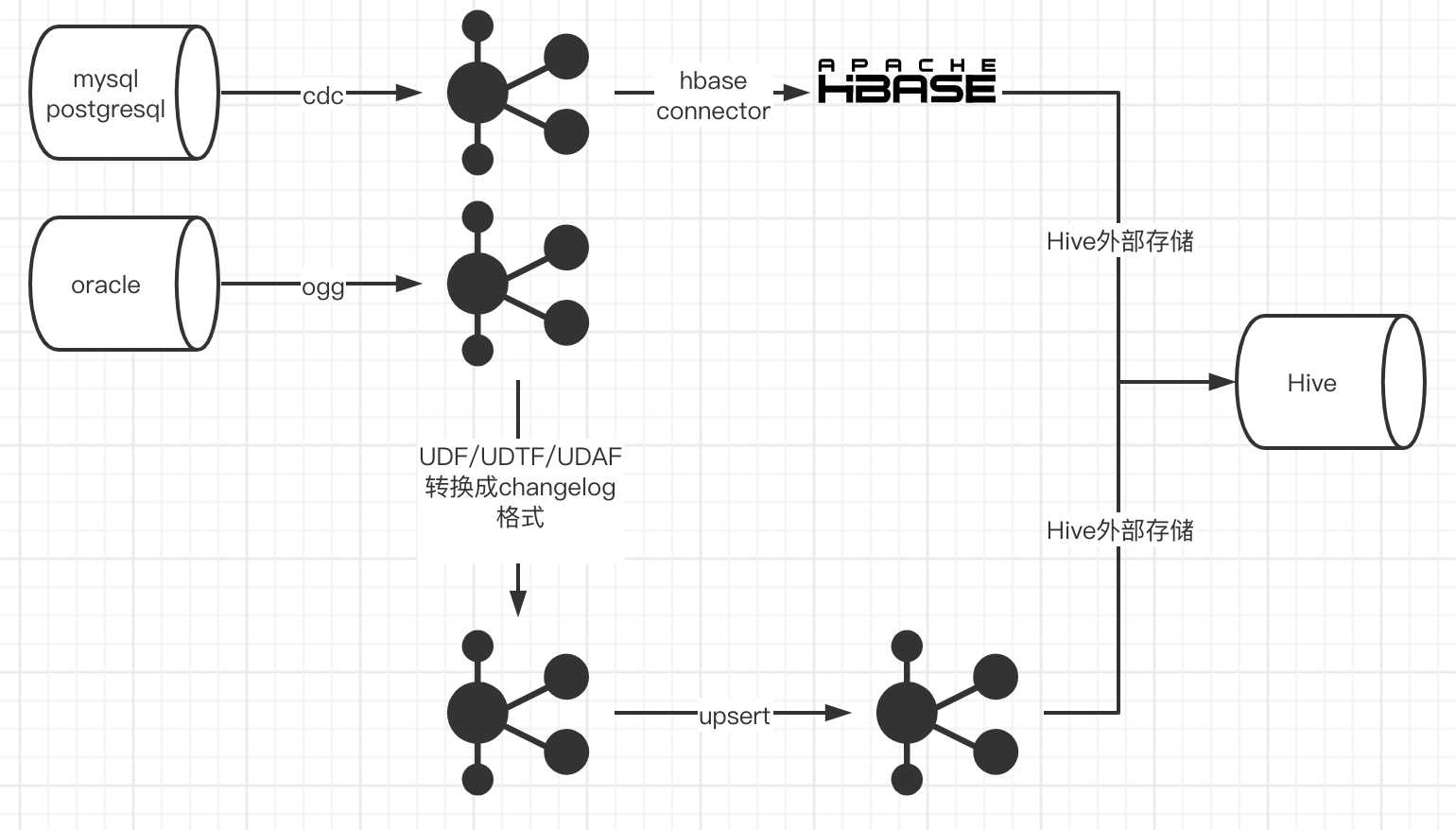
为什么选择Hbase中转,而不是直接入Hive?
因为Hive不支持更新操作,Hbase可以,当然ES也可以作为中转组件oracle接入为什么这么复杂?
因为flink对oracle cdc的支持还在测试中,flink cdc其实封装了debezium和kafka,对于debezium接入oracle数据,还在等debezium出稳定版的oracle接入。我们需要把kafka的数据转换成flink识别的change log,然后才能使用Hbase connector,在hbase中做更新删除操作。不支持的cdc数据源怎么办?
自定义source,只要数据进入到了kafka,一切都好说。
实时数据接入,目标就是将业务库(mysql oracle mongo postgresql等)数据库中的数据拉取到数据仓库中,供实时计算使用,那么如何接入呢,flink提供了许多方式,且看:
- cdc:sql方式,但是目前只支持mysql和pg,其他数据库正在开发测试中;
- Api:通过写代码方式接入数据,可以接入许多数据库、消息组件的数据,例如jdbc方式连接的数据库,kafka,rabbitmq等;
- 自定义source:实现接口SourceFunction
cdc方式全程sql,即可接入到StreamTable中。
一般大公司,为了降低开发成本,提高效率,都希望使用sql方式完成工作,但是flink sql支持不太完善,许多功能需要自己去实现,下面来看看其他数据源如何接入:
- 比如我们的数据源是从oracle来的,flink暂不支持oracle方式的cdc,那么可以通过oracle ogg将update delete insert类型的change log,写入kafka,然后将kafka中的message,通过udf、udtf方式转化成flink识别的changelog,格式为{“data”: {}, “op”: “”},op有4中类型:+I,-U,+U,-D
- kafka:kafka connector
- changelog:kafka changelog connector
- hbase:hbase connector,目前hbase只支持1.4和2.2版本
- hive:hive connector
- es:es connector,不支持source,只支持sink
相关参考链接:
flink_table_connector
如有什么问题,欢迎联系我:
微信:PAIN_7771
qq: 2536888617
邮箱:chenzuoli709@163.com
永远保持思考,居安思危。
欢迎关注微信公众号:【程序员写书】
喜欢宠物的朋友可以关注:【电巴克宠物Pets】
一起学习,一起进步。