
flink作为一个计算引擎,是缺少存储介质的,那么数据从哪儿来,到哪儿去,就需要连接器了,链接各种类型数据库,各种类型组件进行数据的抽取、计算、存储等,下面来看看flink都有哪些connector,怎么使用的?

介绍
看看目前支持的connector:
这是官方给出的: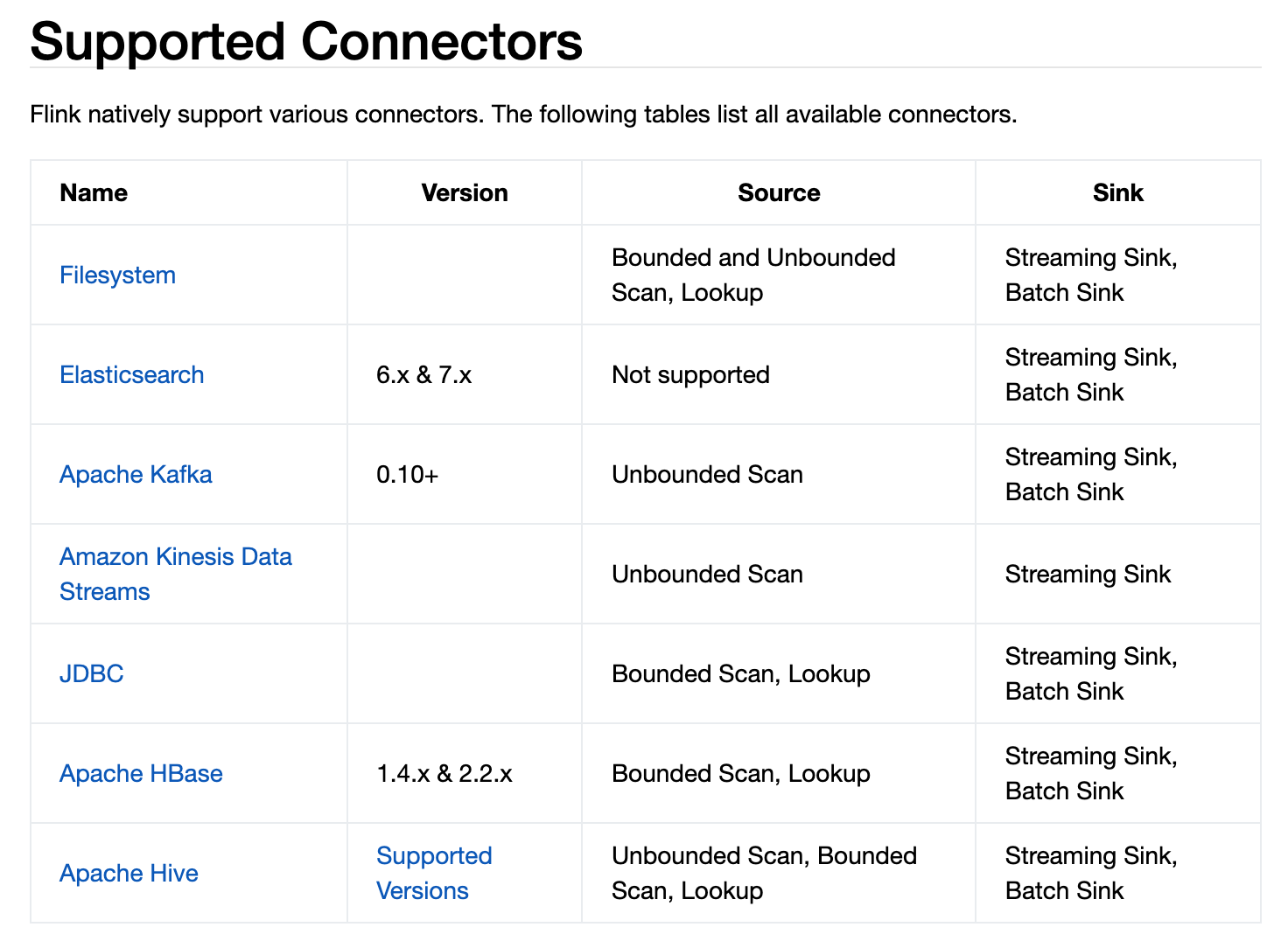
有些支持数据源,有些不支持数据源,有些支持无边界流式处理,有些不支持,具体看上图。
我们目前市面上用的比较多的数据库,大概是以下几种:
1 | # 支持jdbc |
使用
kafka
1 | CREATE TABLE MyUserTable ( |
hbase
注意hbase目前只支持1.4和2.2版本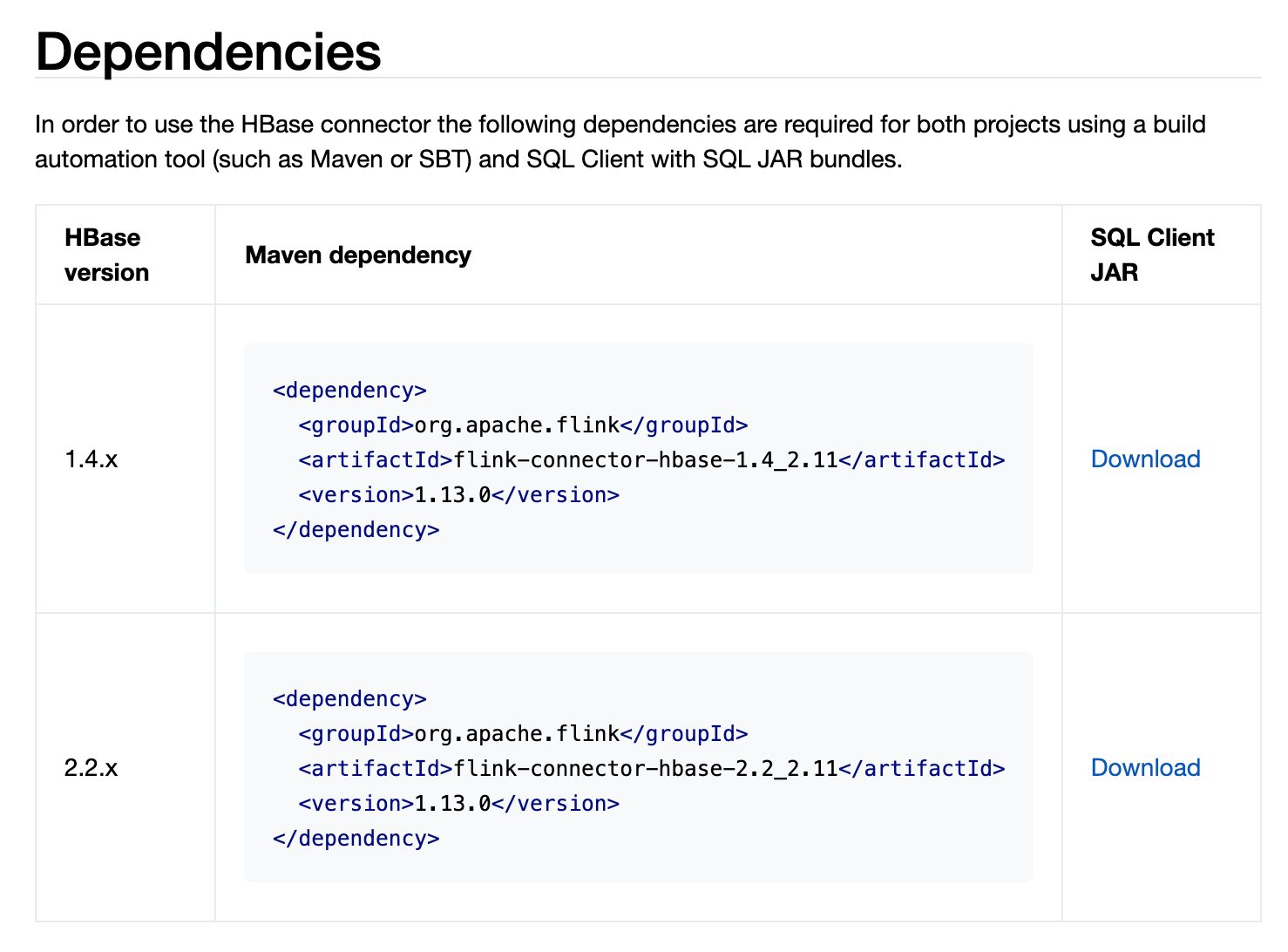
1 | -- register the HBase table 'mytable' in Flink SQL |
jdbc
jdbc连接需要添加对应的driver到flink lib里
mysql:点这里
postgresql:点这里
oracle:点这里下载ojdbc8.jar
这是常用的,其他的在网上都能搜得到
1 | -- register a MySQL table 'users' in Flink SQL |
es
es只能做sink不能做source
1 | CREATE TABLE myUserTable ( |
文件
可以是服务器本地文件,也可以是hdfs文件,区别就是文件路径描述符的区别:
1 | CREATE TABLE MyUserTable ( |
另外还有几种特殊的connector:
datagen
datagen会按照字段指定的类型,随机生成对应的数据
1 | CREATE TABLE Orders ( |
每一个写入该表的数据,都会标准输出到日志里
1 | CREATE TABLE print_table ( |
blackhole
这个connector会吞噬一切数据,往这个表里写的数据都会消失,主要用于测试性能。
1 | CREATE TABLE blackhole_table ( |
参考官网链接:
flink connectors
其实每个connector都支持指定类型的format格式方式,下期文章介绍如何指定格式化,可以指定那些格式化。
点个关注呗。
不积跬步无以至千里,不积小流无以成江海。
欢迎关注我的微信公众号,比较喜欢分享知识,也喜欢宠物,所以做了这2个公众号:
喜欢宠物的朋友可以关注:【电巴克宠物Pets】
一起学习,一起进步。