
记录下用python处理图片中的文字字幕。
介绍
Tesseract 是一个非常流行的OCR(光学字符识别)引擎,由Google支持。Tesseract能够从图像文件中识别和提取纯文本。它主要用于处理PDF文件和各种图像格式,如PNG、JPG、TIFF等,识别多种语言的文字。
以下是Tesseract的一些关键特点:
多语言支持:Tesseract支持超过100种语言,包括中文,并且社区还提供了额外的语言训练数据。
命令行工具:Tesseract主要通过命令行界面使用,这使得它可以很容易地集成到其他应用程序中。
开源:Tesseract是开源软件,可以在Apache 2.0许可下免费使用。
可定制的PSM(页面分割模式):Tesseract允许用户指定页面布局的假设,例如,是否为单栏或双栏文本,是否包含标题等。
支持多种图像格式:可以处理多种图像格式,包括但不限于PNG、JPG、TIFF等。
配置选项:Tesseract提供了丰富的配置选项,允许用户调整识别精度,如调整阈值、进行去噪处理等。
与Leptonica结合使用:Tesseract经常与Leptonica图像处理库一起使用,Leptonica提供了大量的图像处理功能,可以用来提高OCR前的图像质量。
开发者社区:有一个活跃的开发者社区,不断有新的贡献和改进。
环境
macos bigsur 11
python 3.8.9
pytesseract-0.3.10
系统tesseract版本 5.3.3
安装
1 | pip install pytesseract==0.3.10 |
tesseract-eng这个是英语语言模型,只能识别图片中的英文,如果需要支持中文,我按照文档安装了中文模型,但是不起作用:
1 | # 简体中文 |
1 | tesseract 1_DPI1000.jpg chi -l chi_sim |
无法识别图片中的中文
寻找到另一个中文模型,需要自己下载中文模型:
https://github.com/tesseract-ocr/tessdata_best/blob/main/chi_sim.traineddata
查看已安装的语言模型:
1 | tesseract --list-langs |

这里可以看到语言模型安装的位置。
将下载的中文模型文件,放到这个目录位置。
/opt/local/share/tessdata/
1 | wget https://github.com/tesseract-ocr/tessdata_best/blob/main/chi_sim.traineddata |
这里是支持的所有语言列表:
https://ports.macports.org/search/?q=tesseract-&name=on
问题
安装完tesseract后,运行tesseract –version报错
显示libpng16版本较低,显示libpng16 没有被加载:
1 | dyld: Library not loaded: /opt/local/lib/libpng16.16.dylib |
后面发现问题了: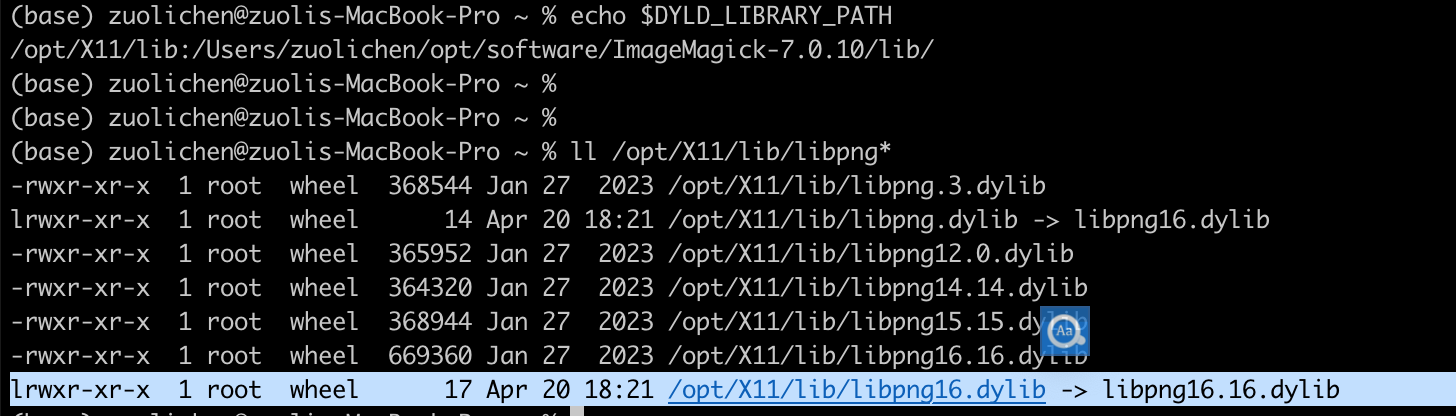
我不知道为什么设置了 DYLD_LIBRARY_PATH 变量,这个变量里包含了libpng16.16.dylib,导致了libpng16版本加载问题。
解决办法:
1 | unset DYLD_LIBRARY_PATH |
就ok了。
识别图片中文字
基本的Tesseract使用示例如下:
1 | tesseract image.png output.txt |
这条命令会处理名为image.png的图像文件,并把识别出的文本保存到output.txt文件中。
Tesseract也支持通过配置文件来调整识别参数,例如:
1 | tesseract image.png output -l chi_sim+eng --oem 2 --psm 6 |
在这个例子中,-l 指定了使用的语言模型(这里是简体中文加英文),--oem 指定了OCR引擎模式(这里是精确识别),--psm 指定了页面分割模式(这里是假设页面是统一的文本块)。
Tesseract非常适合需要将扫描文档或图片转换成可编辑文本的情况,是许多开发者和数据科学家在进行自动化文档处理时的首选工具。
欢迎关注微信公众号,你的资源可变现:【乐知付加密平台】
一起学习,一起进步。